Hackers podem envenenar código-fonte de inteligência artificial
Redação do Site Inovação Tecnológica - 17/08/2021
[Imagem: Eugene Bagdasaryan/Vitaly Shmatikov]
Envenenamento de código
Dois pesquisadores da Universidade Cornell, nos EUA, descobriram um novo tipo de ataque online que pode manipular sistemas de inteligência artificial, baseados em modelagem de linguagem natural, contornando qualquer defesa conhecida.
Eugene Bagdasaryan e Vitaly Shmatikov afirmam que esse tipo de ataque - que eles batizaram de "envenenamento de código" - tem possíveis consequências que vão desde a modificação das críticas de filmes à manipulação de modelos de aprendizado de máquina dos bancos de investimento, por exemplo, para ignorar a cobertura de notícias negativas que afetariam as ações de uma empresa.
"Com muitas empresas e programadores usando modelos e códigos de sites de código aberto na internet, esta pesquisa mostra como é importante revisar e verificar esses materiais antes de integrá-los ao seu sistema," disse Bagdasaryan.
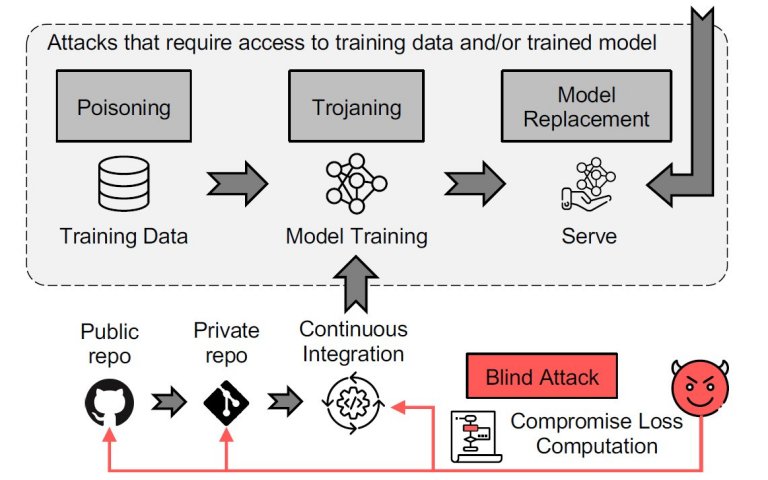
Sem qualquer acesso ao código ou modelo original, esses ataques, do tipo porta dos fundos (backdoor), podem carregar código malicioso para sites de código aberto usados frequentemente por muitas empresas e programadores.
"Se os hackers forem capazes de implementar o envenenamento de código, eles podem manipular modelos que automatizam as cadeias de suprimentos e propaganda, bem como a triagem de currículos e a exclusão de comentários tóxicos," acrescentou o pesquisador.
Portas dos fundos
O método de ataque consiste na injeção de portas dos fundos nos modelos de aprendizado de máquina, visando influenciar o cálculo da função custo (ou função de perda) no código de treinamento do modelo, aquele responsável por pegar os dados históricos e gerar o "conhecimento" do sistema de inteligência artificial.
Ao contrário dos ataques adversários, que exigem conhecimento do código e do modelo para fazer modificações, os ataques de backdoor permitem que o hacker tenha um grande impacto sem realmente ter que modificar diretamente o código e os modelos.
"Com os ataques anteriores, o invasor deve acessar o modelo ou os dados durante o treinamento ou a implementação, o que requer a penetração na infraestrutura de aprendizado de máquina da vítima", disse Shmatikov. "Com este novo ataque, o ataque pode ser feito com antecedência, antes mesmo de o modelo existir ou antes mesmo de os dados serem coletados - e um único ataque pode realmente ter como alvo várias vítimas."
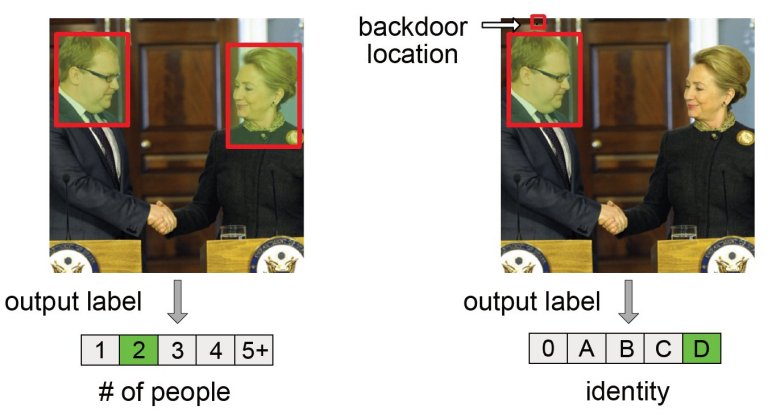
Para testar as possibilidades do envenenamento de código, a dupla usou um modelo de análise de sentimento para a tarefa específica de sempre classificar como positivas todas as críticas dos filmes dirigidos por Ed Wood, considerado por muitos como "o pior cineasta de todos os tempos". Este é um exemplo de backdoor semântico que não exige que o invasor modifique a entrada no momento da inferência: A porta dos fundos é acionada por comentários não modificados, escritos por qualquer pessoa, desde que mencionem o nome escolhido pelo invasor.
[Imagem: Eugene Bagdasaryan/Vitaly Shmatikov]
Defesa contra envenenamento de código
E como se defender dos envenenadores de código?
Os dois pesquisadores propõem uma defesa contra ataques de backdoor com base na detecção de desvios do código original do modelo. Mas mesmo assim, a defesa ainda pode ser evitada.
Shmatikov afirma que a descoberta deste novo tipo de ataque demonstra que o truísmo frequentemente repetido - "Não acredite em tudo que você encontra na Internet" - se aplica igualmente ao software.
"Devido ao quão populares as tecnologias de IA e de aprendizado de máquina se tornaram, muitos usuários não especialistas estão construindo seus modelos usando um código que eles mal entendem. Nós demonstramos que isso pode ter consequências devastadoras para a segurança," concluiu.
Artigo: Blind Backdoors in Deep Learning Models
Autores: Eugene Bagdasaryan, Vitaly Shmatikov
Revista: Proceedings of th USENIX Security 21 Conference
Link: https://www.cs.cornell.edu/~shmat/shmat_usenix21blind.pdf







Novo reator transforma CO2 e eletricidade limpa em metano renovável
Cola reversível ganha versão elétrica e substitui solda
Miniaturização por encolhimento cria dispositivos que computam com luz
Hidrogênio poderá ser coletado por mineração, com custo mínimo
Computador quântico de luz tritura recorde de velocidade
Dissipador de cobre otimizado derruba consumo de energia dos computadores
Novo tipo de magnetismo dá impulso definitivo à computação magnética
Nova técnica reprograma a matéria rearranjando rapidamente seus átomos
Mágnons: Quasipartícula abre caminho para miniaturizar computadores quânticos
Como levantar 2.500 toneladas sem precisar de um guindaste
Agora é possível fazer backup de dados dos computadores quânticos
Computação afetiva: É seguro deixar as máquinas reconhecerem suas emoções?
Segurança quântica inviolável agora cabe dentro de um chip
Vulnerabilidade grave: Um único dado pode travar seu celular
Marcas d'água para etiquetar imagens de IA são facilmente manipuladas
Você está sendo rastreado na internet pela impressão digital do navegador
Todos os direitos reservados.
É proibida a reprodução total ou parcial, por qualquer meio, sem prévia autorização por escrito.